Programmieren in C++: Einführung
Kapitel 7: Zeiger
Inhaltsverzeichnis
![]() Dieses Buch ist unter einer Creative Commons-Lizenz lizensiert.
Dieses Buch ist unter einer Creative Commons-Lizenz lizensiert.
7.1 Allgemeines
Anfänger mögen keine Zeiger
Wenn Sie jemanden fragen, der momentan die Programmiersprache C oder C++ erlernt, was er von Zeigern hält, wird er sich entweder lautstark über Zeiger beschweren oder über Sie, weil Sie es gewagt haben, ihn an das Thema Zeiger zu erinnern. Viele Einsteiger in C und C++ halten Zeiger für einen der am schwierigsten zu erlernenden Bestandteile dieser Programmiersprachen und zerbrechen sich den Kopf darüber, Sinn und Zweck und die Funktionsweise von Zeigern zu verstehen.
Woran liegt das? Wer Zeiger verstehen will, muss grundlegende Kenntnisse zur Funktionsweise des Computers besitzen. Sie müssen kein Experte für Chiptechnologien sein. Da Zeiger irgendwas mit Variablen zu tun haben, müssen Sie aber wissen, wie Variablen intern im Computer verwaltet werden. Es reicht nicht mehr aus, sich wie im Kapitel 2, Variablen unter Variablen irgendwelche Töpfe vorzustellen, sondern wir müssen einen zweiten Schritt machen, um Zeiger in unserem Variablen-Modell unterzubringen.
Selbst wenn Sie als Hardware-Experte wissen, wie ein Computer intern funktioniert, verzweifeln Sie möglicherweise dennoch an Zeigern. Im Zusammenhang mit Zeigern fallen immer wieder Begriffe wie Variable, Adresse, Adressoperator, Verweisoperator und so weiter, die alle eine ganz klare Bedeutung haben und scharf getrennt werden müssen. Zu allem Überfluss sehen der Adress- und der Verweisoperator auch noch anderen Operatoren in C++ zum Verwechseln ähnlich. Einsteiger haben häufig Schwierigkeiten, den Zusammenhang zwischen diesen Begriffen zu verstehen und die Operatoren klar auseinanderzuhalten - und kommen so nur allzu leicht durcheinander.
Um die interne Arbeitsweise des Computers im Hinblick auf Variablen nachvollziehen zu können und gleichzeitig Ordnung in das Begriffschaos zu bringen, bevor es ausbricht, wäre ein einfaches, einleuchtendes Modell hilfreich, das die Komplexität hinter Zeigern durchschaubar macht. Im nächsten Abschnitt steigen wir genau mit einem derartigen Modell in die Zeigerprogrammierung ein.
7.2 Variablen-Modell
Identifikation von Variablen auf zwei Wegen
Um uns an Zeiger heranzutasten, beginnen wir mit einem kurzen Rückblick über Variablen. Im Kapitel 2, Variablen hatten Sie Variablen kennengelernt. Sie hatten gelernt, dass Variablen verwendet werden, um in einem Programm Informationen zu speichern. Unter Variablen haben Sie sich ganz einfach Töpfe vorstellen können, wobei jeder einzelne Topf jeweils eine Information speichern kann. Folgende Grafik zeigt vier Variablen in Form von Töpfen.

Um jeweils auf eine bestimmte Variable zugreifen zu können, ist es wichtig, Variablen identifizieren zu können. Dies geschieht über Variablennamen. In obiger Grafik heißen die vier Töpfe A, B, C und D. Die Variablennamen sind auf den Töpfen aufgeklebt, um auf diese Weise die Töpfe identifizieren zu können.
Nachdem Sie gelernt hatten, was Variablen sind, wurden Sie mit Datentypen vertraut gemacht. Ein Datentyp gibt an, welche Art von Information in einer Variablen gespeichert werden kann. Je nach Datentyp kann eine Variable zum Beispiel nur ganze Zahlen speichern, Wahrheitswerte oder Zeichenketten. Es gibt in C++ also keine Variablen, die jede beliebige Art von Information speichern können, sondern nur strengtypisierte Variablen: In dem Moment, in dem Sie eine Variable anlegen - sprich einen Topf herbeizaubern - müssen Sie über die Angabe des Datentypen gleichzeitig festlegen, welche Art von Information in der Variable gespeichert werden können soll.
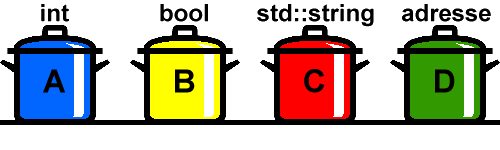
Die Grafik berücksichtigt nun Datentypen. Es handelt sich bei den vier Variablen nun nicht mehr um die gleichen Töpfe, die gleiche Informationen speichern können, sondern jeder Topf ist unterschiedlich und kann unterschiedliche Informationen speichern. In der Grafik wird dies durch die unterschiedlichen Farben der Töpfe dargestellt. Um die Bedeutung der Farbe zu verdeutlichen, ist außerdem über den Töpfen jeweils ein anderer Datentyp angegeben: Variable A ist vom Typ int und kann Ganzzahlen speichern. Variable B ist vom Typ bool und kann Wahrheitswerte speichern. Variable C besitzt den Datentyp std::string aus dem C++-Standard. Der Datentyp std::string ermöglicht die Speicherung beliebiger Zeichenketten, also zum Beispiel von Wörtern, Sätzen oder ganzen Büchern. Die Variable D basiert letztendlich auf einem Datentyp namens adresse, der vom Programmierer zum Beispiel in Form einer Struktur selbst erstellt werden müsste.
Werden die Datentypen wie in der Grafik angegebenen den vier Töpfen zugewiesen, bedeutet das zum Beispiel, dass die Information 169 - also die Ganzzahl 169 - im blauen Topf gespeichert werden könnte, nicht aber in den anderen drei Töpfen. Die Ganzzahl 169 ist nur mit dem Datentypen int kompatibel, nicht mit den Datentypen bool, std::string und adresse.
int A; bool B; std::string C; adresse D; A = 169;
Damit Sie vor lauter Töpfen den eigentlichen C++-Code nicht vergessen, sehen Sie oben, wie die in der Grafik angegebenen vier Variablen in C++ angelegt werden und in der Variablen A die Zahl 169 gespeichert wird. Der Datentyp adresse müsste selbstverständlich vom Programmierer zuerst definiert werden, bevor er zur Definition der Variablen D verwendet werden könnte. Auch für den Datentyp std::string gilt, dass er erst bekannt gemacht werden muss, bevor er verwendet werden kann.
Bis jetzt sollte Ihnen alles bekannt vorkommen. Sehen Sie sich nun nochmal obige Grafik mit den vier farbigen Töpfen an. Jeder Topf kann über seinen Namen, hier jeweils in Form eines Buchstabens, identifiziert werden. Gucken Sie sich die Grafik genau an. Gibt es noch eine andere Möglichkeit, Töpfe zu identifizieren?
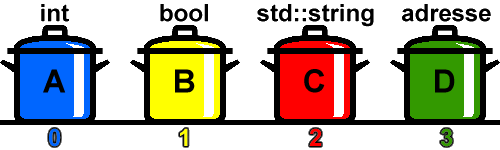
Es gibt sie! Töpfe stehen an ganz bestimmten Positionen, und über die Positionsnummer kann ebenfalls ein Topf ganz klar identifiziert werden. So steht in der Grafik Topf A an Position 0, Topf B an Position 1, Topf C an Position 2 und Topf D an Position 3. Die Positionsnummer ist jeweils unter den Töpfen in der Grafik angegeben. Wenn Sie also nun die Zahl 169 in einem Topf speichern wollen, können Sie sie entweder in den Topf A ablegen oder aber in den Topf, der an Position 0 steht. Egal, ob Sie auf Topf A oder auf den Topf an Position 0 zugreifen, in beiden Fällen würde auf den gleichen blau angestrichenen Topf zugegriffen werden. Es gibt also in C++ (wie auch in C) zwei Möglichkeiten, Variablen eindeutig zu identifizieren: Über ihren Namen und über ihre Position.
Dass Variablen tatsächlich über ihre Position identifiziert werden können, liegt an der internen Arbeitsweise des Computers. Wann immer Sie eine Variable anlegen, muss der Computer Speicherplatz für diese Variable bereitstellen. Denn wenn Sie eine Information in die Variable legen, muss diese Information ja vom Computer tatsächlich irgendwo gespeichert werden.
Speicherplatz wird für Variablen im RAM reserviert. RAM steht für Random Access Memory. Die Abkürzung RAM kennen Sie möglicherweise aus Anzeigen von Computerherstellern: Die Größe des RAMs, gemessen in Megabyte, ist eine der technischen Eckdaten, auf die beim Kauf von Computern geachtet werden muss. So sind heutige Computer zum Beispiel häufig mit rund 1000 Megabyte RAM ausgerüstet - je mehr, desto besser.
Wenn Sie eine Variable anlegen, wird für diese vom Computer im RAM Speicherplatz reserviert. Mal angenommen, Sie legen eine Variable vom Typ int wie folgt an.
int A;
Eine int-Variable ist 4 Byte groß. In Ihrem rund 1000 Megabyte großen RAM werden also mit obiger Zeile 4 Byte für die Variable A reserviert. Während Sie als Programmierer praktischerweise mit dem Variablennamen A arbeiten können, um auf die reservierten 4 Byte zuzugreifen und dort eine Ganzzahl abzulegen, muss der Computer sich jedoch merken, wo genau in den 1000 Megabyte des RAMs eigentlich die 4 Byte für die Variable A liegen. Und das geschieht über die Position der 4 Byte im RAM.
Sie sehen, das Modell mit den Töpfen und den Positionsnummern ist nicht aus der Luft gegriffen. So wie die vier Töpfe über die Buchstaben A, B, C und D oder aber über ihre Positionsnummer identifiziert werden können, können auch Variablen im RAM über den Variablennamen oder aber über ihre Position identifiziert werden. Im Allgemeinen zieht man den Variablennamen zur Identifikation vor, weil man ihn sich nicht nur besser merken kann als irgendeine Nummer, sondern weil er auch viel aussagekräfter ist. Warum man dennoch Positionsnummern verwendet und manchmal sogar verwenden muss, und was Positionsnummern eigentlich mit Zeigern zu tun haben, werden Sie im Laufe dieses Kapitels erfahren.
Wenn im nächsten Abschnitt auf Begriffe wie Adressen und Zeiger eingegangen wird, halten Sie sich immer unser Variablen-Modell mit den vier Töpfen vor Augen. Das Modell soll Ihnen helfen, die Zusammenhänge nicht aus den Augen zu verlieren. Wenn das klappt, ist für Sie auch das etwas knifflige Thema dieses Kapitels rund um Zeiger kein Problem.
7.3 Adressen und Zeiger
Positionsnummern in Variablen speichern und über sie auf Variablen zugreifen
Sehen Sie sich nochmal die Grafik mit den vier Töpfen und Positionsnummern an. Jeder Topf kann über einen Namen und über seine Positionsnummer identifiziert werden.
Wie Sie nun wissen gilt dies ebenfalls für Variablen. Wo bekommen Variablen ihren Namen und ihre Positionsnummer her?
Den Variablennamen vergeben Sie. Sie als Programmierer legen bei der Definition einer Variablen nicht nur den Datentyp fest, sondern auch immer den Variablennamen. Sie haben also die alleinige Kontrolle über Variablennamen und können Variablen nennen, wie Sie wollen.
Die Positionsnummer einer Variablen wird hingegen vom Computer vergeben. Wie Sie im vorherigen Abschnitt erfahren haben, reserviert der Computer im RAM Speicherplatz für eine Variable. Wo genau im RAM dieser Speicherplatz reserviert wird, entscheidet ganz allein der Computer. Sie als Programmierer können die Positionsnummer für Variablen jedenfalls nicht vergeben.
Die Programmiersprachen C und C++ ermöglichen es Ihnen jedoch, die Positionsnummer einer Variablen im RAM abzurufen. Während Sie also eine Positionsnummer nicht selber vergeben können, können Sie so die Positionsnummer einer Variablen immerhin in Erfahrung bringen. Dies geschieht mit Hilfe des Adressoperators &.
Das & heißt deswegen Adressoperator, weil in den Programmiersprachen C und C++ genaugenommen nicht von Positionsnummern die Rede ist, sondern von Adressen. Variablen besitzen also jeweils eine ganz bestimmte Adresse, und diese Adresse können Sie mit dem Adressoperator & abfragen. In diesem Kapitel wird auch weiterhin häufig von Positionsnummern die Rede sein, weil dies unserem praktischen Vorstellungsvermögen etwas mehr entgegenkommt als der Begriff Adresse.
Möglicherweise wundern Sie sich, dass der Adressoperator & genauso aussieht wie der Operator für die bitweise UND-Verknüpfung, der im Kapitel 3, Operatoren vorgestellt wurde. Tatsächlich kann das & sowohl Adressoperator als auch bitweise UND-Verknüpfung bedeuten. Es ist nur aus dem Zusammenhang im Quellcode erkennbar, ob das & an einer bestimmten Stelle im Code nun tatsächlich den Adressoperator meint oder aber die bitweise UND-Verküpfung. Grundsätzlich gilt: Die bitweise UND-Verknüpfung ist ein binärer Operator, der links und rechts vom & einen Wert oder eine Variable erwartet. Beim Adressoperator steht links vom & niemals ein Wert oder eine Variable. Sie werden nach einiger Übung die beiden Operatoren aber automatisch auseinanderhalten können.
#include <iostream>
int main()
{
int A;
std::cout << &A << std::endl;
}
Im obigen Code-Beispiel wird eine Variable vom Typ int angelegt. Der Variablenname ist vom Programmierer auf A gesetzt worden. Wenn das Programm gestartet wird, reserviert der Computer für die Variable A im RAM Speicherplatz. Es werden genau 4 Byte reserviert, da der Datentyp der Variablen A int ist und ein int in C++ per Definition immer 4 Byte groß ist. Wo jedoch diese 4 Byte im RAM genau reserviert werden, können wir im Code nicht festlegen. Das entscheidet allein der Computer.
Nachdem die Variable A definiert und der Speicherplatz im RAM reserviert ist, geben wir in der nächsten Zeile die Positionsnummer der Variablen A auf die Standardausgabe aus. Um auf die Positionsnummer einer Variablen zugreifen zu können, muss man den Adressoperator & dem Variablennamen voranstellen. Auf diese Weise wird die Positionsnummer des 4-Byte-Blocks im RAM auf den Monitor ausgegeben. Der Compiler erkennt im Zeichen & den Adressoperator, weil vor ihm kein Wert und keine Variable steht, wie es die bitweise UND-Verknüpfung verlangen würde.
Die Positionsnummer hängt davon ab, an welcher Stelle der Computer die int-Variable im RAM angelegt hat. Es ist nicht möglich, die Positionsnummer vorherzusagen. Wenn Sie das Programm mehrmals oder auf verschiedenen Computern starten, stellen Sie fest, dass bei jedem Programmstart unter Umständen eine andere Positionsnummer ausgegeben wird. Sie haben als Programmierer keinerlei Einfluß auf die Position des reservierten Speichers einer Variablen im RAM.
Nachdem Sie die Positionsnummer der Variablen A auf den Monitor ausgegeben haben, werden Sie im nächsten Code-Beispiel die Positionsnummer zuerst in einer anderen Variablen speichern und dann ausgeben. Positionsnummern scheinen bisher nur ganzzahlige Werte gewesen zu sein. Um also eine Positionsnummer in einer Variablen speichern zu können, könnte man auf die Idee kommen, dieser Variablen zum Beispiel den Datentyp short oder int zu geben - denn diese Datentypen sind ja mit ganzzahligen Werten kompatibel. Leider funktioniert das nicht. Und um zu verstehen, warum das nicht funktioniert, wird es jetzt etwas knifflig. Aber immer schön der Reihe nach.
#include <iostream>
int main()
{
int A;
int* a = &A;
std::cout << a << std::endl;
}
Wie im vorherigen Code-Beispiel wird wieder eine Variable A vom Typ int angelegt. In der zweiten Zeile wird ebenfalls wieder über den Adressoperator & auf die Positionsnummer der Variablen A im RAM zugegriffen. Diese Positionsnummer wird nun jedoch nicht mehr auf den Monitor ausgegeben, sondern einer anderen Variablen namens a zugewiesen. Der Datentyp der Variablen a sieht hierbei etwas ungewöhnlich aus. Das int kennen Sie ja. Was aber soll int* bedeuten?
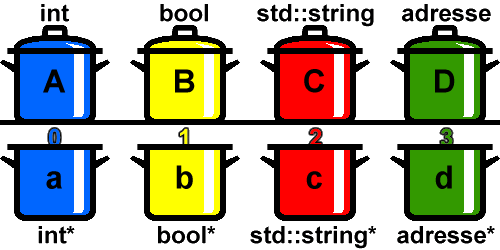
Werfen wir wieder einen Blick auf unser Variablen-Modell mit den vier Töpfen. Mit dem Adressoperator & erhalten wir jeweils die Positionsnummer einer Variablen. Die Positionsnummern sind unterhalb der vier Töpfe A, B, C und D angegeben. Wenn Sie sich die Positionsnummern ansehen, stellen Sie fest, dass es sich hierbei scheinbar ausschließlich um Ganzzahlen handelt. Das macht auch Sinn, da eine Variable entweder an der Position 0 oder an der Position 1 steht, nicht aber an der Position 0,5.
Wenn man nun die Positionsnummer einer Variablen, die man mit dem Adressoperator & ermittelt, in einer anderen Variablen speichern will - genau das wollen wir im obigen Code-Beispiel ja tun - könnte man meinen, dass der geeignete Datentyp für die Speicherung von Positionsnummern zum Beispiel int ist - alle Positionsnummern sind ja schließlich Ganzzahlen. Leider ist das nun nicht so einfach. Es stimmt zwar, dass alle Positionsnummern Ganzzahlen sind. Der Datentyp einer Positionsnummer hängt jedoch davon ab, welchen Datentyp die Variable hat, die an der Position steht.
Sehen wir uns zum Beispiel Topf A an. Topf A hat den Datentyp int. Die Positionsnummer von Topf A ist 0. 0 ist eigentlich eine Ganzzahl, und Ganzzahlen können ja eigentlich in Variablen vom Typ int gespeichert werden. Da unsere 0 aber keine gewöhnliche Ganzzahl ist, sondern eine Positionsnummer, hängt der Datentyp unserer 0 mit dem Datentyp der Variablen zusammen, die an der Position 0 steht - also mit dem Datentyp des Topfes A. Der Datentyp von Topf A ist int. Indem nun hinter diesem Datentypen ein * gesetzt wird, erhalten Sie den Datentyp für die Positionsnummer 0. Eine Variable a, die in unserem Beispiel die Positionsnummer 0 speichern soll, muss den Datentyp int* erhalten, da an der Position 0 eine int-Variable steht. Das ist der Grund, warum in obiger Grafik unterhalb des Topfes a, der die Positionsnummer 0 von Topf A speichert, der Datentyp int* angegeben ist.
Wie sieht es mit Topf B aus? Topf B hat den Datentyp bool. Die Positionsnummer ist 1. 1 ist zwar eine Ganzzahl. Da in diesem Fall 1 aber eine Positionsnummer ist, kann nicht einfach der Datentyp int zur Speicherung dieser Positionsnummer verwendet werden. Stattdessen ist es wieder notwendig, den Datentyp der Variablen anzusehen, der an Position 1 steht. An Position 1 steht eine bool-Variable. Also ist der Datentyp, den wir brauchen, um die Positionsnummer 1 zu speichern, bool*. Die Variable b, die die Positionsnummer 1 erhält, besitzt den Datentyp bool*.
Um in einer Variablen die Positionsnummer 2 zu speichern, muss in unserem Beispiel diese Variable den Datentyp std::string* erhalten. Für den Topf D müsste der Datentyp einer Variablen zur Speicherung der Positionsnummer 3 adresse* lauten.
#include <iostream>
int main()
{
int A;
int* a = &A;
std::cout << a << std::endl;
}
Werfen wir wieder einen Blick auf das Code-Beispiel. Dort ist eine Variable A vom Typ int definiert worden. Die Positionsnummer wird in der nächsten Zeile mit dem Adressoperator & ermittelt. Um diese Positionsnummer in einer Variablen a speichern zu können, muss diese Variable den richtigen Datentyp besitzen. Auch wenn Positionsnummern grundsätzlich immer Ganzzahlen sind, ist es nicht richtig, der Variablen a den Datentyp int zu geben. Denn der Datentyp einer Positionsnummer hängt vom Datentyp der Variablen ab, die an der jeweiligen Position steht.
Der Variablen a wird die Positionsnummer von A zugewiesen. An der Positionsnummer von A steht logischerweise die Variable A. Die Variable A hat den Datentyp int. Daraus folgt, dass a den Datentyp int* haben muss. So schwer ist das nicht, oder?
In der letzten Zeile wird der Wert in a, also die Positionsnummer von A, auf die Standardausgabe ausgegeben. Das Programm macht also letztendlich das gleiche wie das Programm zuvor, speichert die Positionsnummer jedoch zuerst in der Variablen a, bevor sie ausgegeben wird.
Vergessen Sie nicht, dass die tatsächlich ausgegebene Zahl jeweils unterschiedlich sein kann, da bei jeder Programmausführung allein der Computer darüber bestimmt, wo genau im RAM der Speicher für die Variable A reserviert wird.
Vielleicht fragen Sie sich, warum eigentlich der Datentyp von Variablen, die Positionsnummern speichern, nicht einfach int sein kann? Positionsnummern sind immer Ganzzahlen, und trotzdem muss man scheinbar umständlicherweise immer auf den Datentyp der Variablen achten, um dessen Positionsnummer sich alles dreht, und das * dahintersetzen. Warum Sie Positionsnummern nicht in Variablen vom Typ int speichern können, werden Sie anhand des folgenden Code-Beispiels verstehen.
#include <iostream>
int main()
{
int A;
int* a = &A;
*a = 169;
std::cout << a << std::endl;
std::cout << A << std::endl;
}
Das Code-Beispiel wurde um zwei Zeilen ergänzt. Nachdem in der Variablen a die Positionsnummer der Variablen A gespeichert wurde, wird in der nächsten Zeile irgendwie auf a zugegriffen und die Zahl 169 zugewiesen. Wenn Sie genau hingucken, sehen Sie, dass die Zahl 169 nicht a zugewiesen wird, sondern *a. Es taucht also schon wieder das ominöse * auf. Was soll das *a aber bedeuten?
Die Variable a speichert die Positionsnummer von A. Wie Sie von unserem Variablen-Modell zu Beginn des Kapitels wissen, kann man auf Variablen zugreifen, indem man sie entweder über ihren Namen identifiziert oder indem man über die Positionsnummer auf die Variable zugreift. Letzteres ist genau das, was im Code-Beispiel passiert. Indem der Variablen a das * vorangestellt wird, greift man auf die Variable zu, die an der Positionsnummer steht, die in a gespeichert ist - also auf A. Die Zahl 169 wird also tatsächlich der Variablen A zugewiesen. Wenn Sie das nicht glauben, führen Sie obiges Beispiel aus. Die letzte Zeile gibt den Inhalt der Variablen A auf den Monitor aus, nämlich 169.
Die folgenden beiden Code-Zeilen wären also im obigen Programm völlig identisch. In beiden Fällen würde das gleiche passieren: Die Zahl 169 wird der Variablen A zugewiesen.
A = 169; *a = 169;
Warum ist es nun wichtig, dass der Datentyp der Variablen a sich nach dem Datentyp der Variablen richtet, dessen Positionsnummer gespeichert wird? Der Grund ist ganz einfach: Woher sollte sonst der Computer wissen, wie groß der reservierte Speicherblock ist, dessen Positionsnummer Sie im Code verwenden? Folgender Code wird Ihnen das näher erläutern.
int A; int* a = &A; *a = 169; short S; short* s = &S; *s = 169;
Im obigen Code werden zwei Variablen A und S angelegt - die eine vom Typ int, die andere vom Typ short. Es werden zwei Variablen a und s definiert, denen mit dem Adressoperator die Positionsnummern von A und S zugewiesen werden. Dann wird über die Verwendung des * und der Positionsnummern in a und s auf die Variablen A und S zugegriffen und dort jeweils der Wert 169 gespeichert.
Die Variable a besitzt den Datentyp int*, die Variable s besitzt den Datentyp short*. Beide Variablen speichern eine Ganzzahl, nämlich eine Positionsnummer. Obwohl beide Variablen a und s also eigentlich den gleichen Typ haben könnten - nämlich zum Beispiel int - darf das nicht der Fall sein. Denn wenn Sie mit *a auf eine Variable zugreifen und mit *s auf eine andere Variable, dann greifen Sie im ersten Fall auf einen 4-Byte-Block im RAM zu, im zweiten Fall auf einen 2-Byte-Block. Denn die Variable a speichert die Positionsnummer einer int-Variablen, und die Variable s speichert die Positionsnummer einer short-Variablen. Ein int ist per Definition 4 Byte groß, ein short 2 Byte. Wenn die Variablen, die Positionsnummern speichern, nicht die richtigen Datentypen besitzen würden - also gemäß den Datentypen der Variablen, deren Positionsnummern gespeichert werden - weiß der Computer nicht, wie groß eigentlich der reservierte Speicherblock an der Position ist, auf die Sie mit *a und *s zugreifen. Die Größe des jeweils reservierten Speicherblocks hängt vom Datentypen ab, und dieser muss mit in die Definition von Variablen einfließen, die Positionsnummern speichern. Das ist der Grund für die auf den ersten Blick merkwürdigen Datentypen mit dem *.
Das * wird übrigens Verweisoperator genannt. Und hier kommt auch endlich der Begriff des Zeigers ins Spiel: Denn über den Verweisoperator lassen sich Zeiger ganz einfach erkennen. Der Datentyp eines Zeigers besitzt immer auch den Verweisoperator. Sie sehen also, dass in den Beispielen soeben bereits Zeiger eingesetzt wurden. Der Verweisoperator bedeutet, dass eine Variable eine Positionsnummer enthält und über diese Positionsnummer auf eine andere Variable verweist. Man könnte auch sagen auf eine andere Variable zeigt - daher der Begriff Zeiger. Indem der Verweisoperator wie im obigen Beispiel vor die Variable a gestellt wird, wird über die Variable a und die in ihr gespeicherte Positionsnummer auf die Variable A verwiesen bzw. auf die Variable A gezeigt. Die Zahl 169 wird deswegen tatsächlich in A gespeichert. Würden Sie den Verweisoperator weglassen, würde 169 in a gespeichert werden - Sie würden also die Positionsnummer in a ändern.
a = 169; *a = 169;
Um sicherzugehen, dass Sie *a verstanden haben, sehen Sie sich obige beiden Zeilen an. In der ersten Zeile wird einer Variablen a die Zahl 169 zugewiesen. a ist also der Name eines Topfes, in dem die Zahl 169 landet. In der zweiten Zeile wird hingegen auf eine Variable zugegriffen, die an der Positionsnummer steht, die in der Variable a gespeichert ist. Man spricht davon, dass auf eine Variable zugegriffen wird, auf die a zeigt. Die Zahl 169 landet also in irgendeiner Variablen, deren Positionsnummer vorher in a gespeichert wurde. Die zweite Zeile ändert die Variable a nicht.
Sie haben jetzt die beiden Operatoren kennengelernt, die im Zusammenhang mit Zeigern eingesetzt werden: & ist der Adressoperator, um die Positionsnummer einer Variablen zu ermitteln. * ist der Verweisoperator, um über eine Variable, in der eine Positionsnummer gespeichert ist, auf eine entsprechende Variable im RAM zuzugreifen. Die Variable, die die Positionsnummer einer anderen Variable speichert, heißt Zeiger. Sie heißt deswegen so, weil sie über ihren Zahlenwert, den sie speichert, auf eine Position im RAM zeigt, an der eine andere Variable steht.
Mehr gibt es zu Zeigern erstmal nicht zu sagen. Im nächsten Abschnitt sollen ein paar Code-Beispiele Ihnen den Einsatz von Zeigern näherbringen, damit Sie sich an die Verwendung der Operatoren & und * gewöhnen.
7.4 Praxis-Beispiele
Mit Adressen und Zeigern rumspielen
Nachdem Sie in die Funktionsweise von Zeigern eingeführt wurden, fragen Sie sich möglicherweise, was das ganze eigentlich soll: Zeiger scheinen keinen wirklichen Nutzen zu bieten, da Variablen ja so wie bisher auch über ihren Namen identifiziert werden können - was wesentlich unkomplizierter ist. Folgendes Code-Beispiel soll Ihnen zeigen, wann Zeiger zum Beispiel nützlich sein können.
#include <iostream>
#include <string>
void func(std::string* s)
{
*s = "Hallo, Welt!";
}
int main()
{
std::string str;
func(&str);
std::cout << str << std::endl;
}
Im obigen Code-Beispiel wird eine Funktion func() definiert, die als einzigen Parameter einen Zeiger auf einen std::string erwartet. Man könnte auch sagen, sie erwartet die Positionsnummer einer Variablen, die den Datentyp std::string besitzt. Beim Aufruf dieser Funktion wird daher innerhalb von main() auch nicht direkt die Variable str an func() übergeben, sondern &str - also die Positionsnummer von str.
Was passiert nun? Die Positionsnummer von str, die mit &str ermittelt wird, wird als Kopie an die Funktion func() übergeben und dort im Parameter s gespeichert. Sie erinnern sich an Kapitel 5, Funktionen, in dem wir gesagt haben, dass in C++ standardmäßig Werte an eine Funktion immer als Kopie übergeben werden.
Wenn nun die Variable s in der Funktion func() die Positiosnummer von str speichert, dann kann über *s auf die Variable zugegriffen werden, deren Positionsnummer in s gespeichert ist - also natürlich auf str. Genau das passiert auch innerhalb von func(): Dort wird über *s auf die Variable str zugegriffen und ihr die Zeichenkette "Hallo, Welt!" zugewiesen. Wenn Sie das Beispiel ausführen, sehen Sie, dass tatsächlich diese Zeichenkette in der letzten Zeile auf den Bildschirm ausgegeben wird.
Mit Zeigern ist es also möglich, in Funktionen auf Variablen zuzugreifen, die in anderen Funktionen definiert sind. Eine Funktion kann eine Variable verändern, die eigentlich nur in einer anderen Funktion verfügbar ist. Obwohl im obigen Beispiel die Variable str nur innerhalb von main() verwendet werden kann, kann durch die Weitergabe der Adresse dieser Variablen an eine andere Funktion diese ebenfalls mit str arbeiten.
Aber kennen wir das nicht schon längst? Im Kapitel 5, Funktionen hatten wir doch den Referenzoperator & kennengelernt, mit dem es möglich ist, Werte an Funktionen nicht als Kopie, sondern als Original zu übergeben. In diesem Fall kann eine Funktion ebenfalls eine Variable verändern, die in einer anderen Funktion definiert ist. Obiges Code-Beispiel könnte also auch genauso gut mit Hilfe des Referenzoperators geschrieben werden und sähe dann wie folgt aus.
#include <iostream>
#include <string>
void func(std::string& s)
{
s = "Hallo, Welt!";
}
int main()
{
std::string str;
func(str);
std::cout << str << std::endl;
}
Wenn Sie das Code-Beispiel ausführen, stellen Sie fest, dass es genauso funktioniert. Zeiger zu verwenden, um anderen Funktionen Zugriff auf lokale Variablen zu verschaffen, macht keinen Sinn, da dies mit Referenzvariablen viel einfacher funktioniert.
Das war nicht immer so. Wenn man sich die Entwicklungsgeschichte der Programmiersprache C++ ansieht, stellt man fest, dass Zeiger schon sehr lange Bestandteil dieser Programmiersprache sind, Referenzen jedoch erst später eingeführt wurden. Früher gab es also nur die Möglichkeit, Zeiger zu verwenden, wenn man anderen Funktionen Zugriff auf lokale Variablen verschaffen wollte. Heutzutage verwendet man in so einem Fall besser wie eben gesehen Referenzen.
Ein anderer Fall, in dem Zeiger verwendet werden könnten, ist eine Funktion, die dem Aufrufer zwei oder mehr Werte als Ergebnis zurückgeben soll. Wie Sie wissen besitzen Funktionen in C++ nur einen einzigen Rückgabewert. Mit Zeigern kann dieses Problem aber gelöst werden.
#include <iostream>
int func(int* i)
{
int j = *i;
*i = 2 * j;
return j / 2;
}
int main()
{
int zahl1 = 10, zahl2;
zahl2 = func(&zahl1);
std::cout << zahl1 << ", " << zahl2 << std::endl;
}
Die Funktion func() erwartet einen Zeiger auf eine Ganzzahl. Diese Ganzzahl wird von func() einmal verdoppelt und einmal halbiert. Sowohl der verdoppelte als auch der halbierte Wert sollen dann von func() an den Aufrufer dieser Funktion zurückgegeben werden.
Der durch 2 geteilte Wert wird wie gewohnt mit return zurückgegeben. Der mit 2 multiplizierte Wert wird hingegen in der Variablen gespeichert, auf die i zeigt. Der Parameter i erhält im obigen Code-Beispiel die Adresse der Variablen zahl1. Somit wird mit *i in der zweiten Zeile in func() auf die Variable zahl1 zugegriffen und in dieser Variablen der verdoppelte Wert gespeichert.
Wahrscheinlich werden Sie einwenden, dass das Beispiel ohne Probleme mit Referenzen geschrieben werden könnte und man auf Zeiger ganz verzichten könnte - Sie haben Recht. Auch hier würde in modernem C++-Code der Einsatz von Referenzen vorgezogen werden.
Aber keine Angst: Sie erlernen den Einsatz von Zeigern nicht nur aus historischen Gründen. Zum einen existiert enorm viel C-Code, auf den Sie als C++-Programmierer möglicherweise zugreifen wollen - so bieten zum Beispiel die Betriebssysteme Windows und Linux eine riesige Zahl an C-Funktionen an, die Sie direkt in C++ aufrufen können. Dummerweise kennt C aber keine Referenzen, so dass Sie hier um den Einsatz von Zeigern nicht herumkommen. Zum anderen gibt es auch in C++ Situationen, in denen der Einsatz von Zeigern zwingend ist und Sie Zeiger nicht durch Referenzen ersetzen können. Solche Situationen werden Sie im nächsten Abschnitt kennenlernen.
7.5 Dynamische Speicherallokation
Computer, wir brauchen Speicher
Bisher haben Sie in diesem Kapitel eigentlich nur Beispiele kennengelernt, in denen Zeiger ohne Probleme durch Referenzen ersetzt werden können. Jeder C++-Programmierer wendet im Zweifelsfall auch lieber Referenzen als Zeiger an, da sie schlichtweg einfacher einzusetzen sind. In diesem Abschnitt, in dem es um die dynamische Speicherallokation geht, kommen wir um die Anwendung von Zeigern aber nicht herum.
Die dynamische Speicherallokation wird in C++ wie auch in C dann angewendet, wenn Sie während der Entwicklung Ihres Programms nicht wissen, wieviel Speicher später der Anwender Ihres Programms tatsächlich benötigt. Stellen Sie sich zum Beispiel vor, Sie entwickeln eine Adressverwaltung. In einem ersten Schritt erstellen Sie eine Struktur, die Adressen speichern kann. In einem zweiten Schritt erstellen Sie ein Array vom Typ Ihrer Struktur, um in diesem Array eine bestimmte Anzahl an Adressen speichern zu können. Ihr Code könnte demnach zum Beispiel wie folgt aussehen.
#include <string>
struct adresse
{
std::string Name;
std::string Ort;
std::string Telefonnummer;
};
adresse Adressen[100];
Im obigen Code gibt es ein fundamentales Problem: Ihr Array Adressen vom Typ der Struktur adresse besteht aus 100 Elementen, was Sie einfach mal so festgelegt haben. Woher wissen Sie aber, dass der Anwender Ihrer Adressverwaltung tatsächlich 100 Adressen speichern will? Vielleicht möchte er lediglich 5 Adressen speichern. In diesem Fall würde eine unglaubliche Speicherverschwendung stattfinden, weil 95 Elemente in Ihrem Array vom Anwender gar nicht verwendet werden. Vielleicht möchte der Anwender jedoch 150 Adressen speichern. Das lässt Ihre Anwendung aber nicht zu, da nur Platz für 100 Adressen zur Verfügung steht.
Die dynamische Speicherallokation hilft nun aus. Denn sie erlaubt es, während der Programmausführung festzustellen, wieviel Speicher vom Programm benötigt wird und beschafft werden muss. Das heißt, Sie als Entwickler geben nicht mehr statisch zum Kompiliervorgang vor, wieviel Speicher reserviert werden muss, sondern Ihr Programm ermittelt dynamisch zur Laufzeit, wieviel Speicher benötigt wird und beschafft werden muss.
Ihre Adressverwaltung könnte nun so umgeschrieben werden, dass sie nicht automatisch Platz für 100 Adressen zur Verfügung stellt, sondern den Anwender beim Programmstart fragt, wie viele Adressen er speichern möchte. Nachdem der Anwender eine Zahl eingegeben hat, reservieren Sie exakt die Menge an Speicherplatz, die für die gewünschte Anzahl zu speichernder Adressen benötigt wird.
#include <string>
#include <iostream>
struct adresse
{
std::string Name;
std::string Ort;
std::string Telefonnummer;
};
int main()
{
int i;
std::cout << "Wie viele Adressen moechten Sie speichern? " << std::flush;
std::cin >> i;
adresse* Adressen = new adresse[i];
for (int j = 0; j < i; ++j)
{
Adressen[j].Name = "Boris Schaeling";
Adressen[j].Ort = "Entenhausen";
Adressen[j].Telefonnummer = "1234567890";
}
delete[] Adressen;
}
Im obigen Code-Beispiel wird der Anwender zuerst gefragt, wie viele Adressen er speichern möchte. Die Zahl, die der Anwender eingibt, wird in der Variablen i gespeichert. Der Wert in der Variablen i wird dann verwendet, um genau die benötigte Menge an Speicherplatz zu reservieren. Dies geschieht im Code-Beispiel mit folgender Anweisung.
adresse* Adressen = new adresse[i];
In dieser Zeile taucht ein Schlüsselwort auf, das Sie bisher noch nicht kennengelernt haben - nämlich new. Es handelt sich hierbei um einen in die Programmiersprache C++ eingebauten Operator, der es ermöglicht, dynamisch Speicher zu reservieren. Das new wird also immer im Zusammenhang mit der dynamischen Speicherallokation verwendet.
Der Operator new wird so angewendet, dass Sie hinter new angeben müssen, wie viel Speicher eigentlich reserviert werden soll. Sie bekommen von new einen Zeiger zurück - oder anders gesagt eine Positionsnummer - der auf den reservierten Speicherbereich im RAM zeigt.
In unserem Code-Beispiel möchten wir mehrere Variablen vom Typ der Struktur adresse definieren, um in ihnen Adressen speichern zu können. Der Anwender unseres Programms hat hierzu einen Wert eingegeben, den wir in der Variablen i gespeichert haben und der uns sagt, wie viele Adressen genau gespeichert werden können sollen. Wir erstellen nun hinter new ein Array vom Typ adresse, das aus genauso vielen Elementen besteht wie in der Variablen i angegeben. Die Positionsnummer des Speicherbereichs, der daraufhin von new reserviert wird, wird von uns in einer Variablen Adressen gespeichert. Diese Variable Adressen hat den Datentyp adresse*, weil die Positionsnummer, die gespeichert wird, auf einen Speicherbereich zeigt, der Informationen vom Typ adresse speichern kann.
Im Code-Beispiel wird daraufhin in einer for-Schleife auf den Speicherbereich zugegriffen, auf den die Variable Adressen zeigt, und den einzelnen Elementen im Array einfach eine Adresse zugewiesen. Sie sehen an der Art des Zugriffs, dass der Zeiger Adressen merkwürdigerweise so angewendet werden kann als würde es sich um ein ganz normales Array handeln. Der Datentyp des Zeigers Adressen ist zwar adresse*, dennoch meckert der Compiler anscheinend nicht, wenn Sie auf Elemente in diesem Speicherbereich mit Adressen[i] zugreifen. Der Grund, warum dies funktioniert, ist, dass Arrays und Zeiger sehr eng miteinander verwandt sind. Man kann in C und C++ aus einem Array einen Zeiger machen und aus einem Zeiger ein Array. Das sind jedoch technische Details, auf die an dieser Stelle nicht weiter eingegangen werden soll, da sie uns vom Thema der dynamischen Speicherallokation weit wegführen würden.
Das Code-Beispiel enthält am Ende der Funktion main() folgende Zeile.
delete[] Adressen;
In der dynamischen Speicherallokation geht es nicht nur darum, Speicher zu reservieren, sondern auch immer darum, reservierten Speicher, der nicht mehr benötigt wird, an das Betriebssystem zurückzugeben. So wie mit new Speicher reserviert werden kann, kann mit dem Operator delete reservierter Speicher wieder freigegeben werden.
Es ist extrem wichtig, dass wenn immer Sie new verwenden irgendwann in Ihrem Programm der reservierte Speicher mit delete freigegeben wird. Sie fordern mit new vom Betriebssystem Speicher an. Computer besitzen nicht unendlich viel Speicher - es handelt sich hierbei um eine begrenzte Ressource. Wenn Sie immer nur Speicher anfordern und nie Speicher an das Betriebssystem zurückgeben, dann könnte es irgendwann zu Speicherknappheit kommen, und Ihr Programm oder andere parallel laufende Programme, die vom Anwender eingesetzt werden, funktionieren nicht mehr richtig, weil einfach der vorhandene Speicher bereits komplett konsumiert wurde und nichts mehr frei ist. Als anständiger Entwickler gehen Sie daher mit Speicher besser vorsichtig um und denken daran, Speicher an das Betriebssystem mit delete zurückzugeben, wenn Sie ihn nicht mehr benötigen.
Der Operator delete funktioniert wie folgt: Sie geben hinter delete einen Zeiger an, der auf den Speicherbereich zeigt - oder anders gesagt der die Positionsnummer des Speicherbereichs enthält - der freigegeben werden soll. Mehr müssen Sie nicht tun.
Beachten Sie, dass Sie hinter delete die eckigen Klammern [] angeben müssen, wenn Sie zuvor mit new ein Array dynamisch reserviert haben. Sonst lassen Sie die eckigen Klammern einfach weg. Sehen Sie sich folgende Beispiele an, die Ihnen den Unterschied zwischen der dynamischen Speicherallokation von Variablen und von Arrays näher bringen sollen.
int *i = new int; *i = 169; delete i; std::string *s = new std::string; *s = "Hallo, Welt!"; delete s; int *a = new int[2]; a[0] = 169; a[1] = 170; delete[] a; std::string *b = new std::string[2]; b[0] = "Hallo"; b[1] = "Welt"; delete[] b;
Die Zeiger i und s verweisen jeweils auf Speicherbereiche, die aus einzelnen Variablen bestehen - einmal int, einmal std::string. Bei der Rückgabe des reservierten Speichers wird daher der Operator delete angewendet - ohne eckige Klammern.
Die Zeiger a und b hingegen verweisen auf dynamisch reservierte Arrays. Sie müssen daher bei der Rückgabe der Speicherbereiche delete[] verwenden - mit eckigen Klammern. Unter Umständen scheint Ihr Programm auch zu funktionieren, wenn Sie die eckigen Klammern weglassen. Sie finden im Internet auch viel C++-Code, der dynamisch reservierte Arrays mit delete zurückgibt. Dieser Code ist jedoch eindeutig falsch. Dass die Programme dennoch scheinbar funktionieren, ist zwar schön. Dass sie das aber nur unter Umständen tun und nicht generell, ist für professionelle Entwickler sicher nicht zufriedenstellend. Merken Sie sich daher unbedingt, dynamisch reservierte Arrays immer mit delete[] zurückzugeben, auch wenn die leeren eckigen Klammern an dieser Stelle etwas merkwürdig aussehen.
Die dynamische Speicherallokation hat ein großes Problem: Man darf als Programmierer nie vergessen, einmal mit new reservierten Speicher irgendwann mit einem delete oder delete[] wieder an das Betriebssystem zurückzugeben. In Programmen, die aus tausenden von Code-Zeilen bestehen und an verschiedenen Stellen Speicher dynamisch reservieren, kann dies allzu leicht passieren.
In C++ wurden daraufhin sogenannte smart pointers erfunden, also intelligente Zeiger, die automatisch Speicher freigeben, der zuvor mit new reserviert wurde. Man kann die dynamische Speicherallokation also wie in diesem Abschnitt vorgestellt anwenden, braucht aber nicht irgendwann selbst als Programmierer mit delete oder delete[] den reservierten Speicher zurückgeben - das geschieht vollautomatisch.
Es gibt verschiedene Arten von smart pointers. Der C++-Standard enthält bisher nur einen einzigen smart pointer namens std::auto_ptr. Dieser kann in unserem Code-Beispiel nicht verwendet werden, da er Speicherbereiche mit delete freigibt und nicht mit delete[]. In der kommenden Version des C++-Standards, die voraussichtlich 2010 erscheinen wird, sind weitere smart pointers enthalten, die es einfacher machen werden, fehlerfreien Code für die dynamische Speicherallokation zu schreiben.
Das Arbeiten mit Zeigern wird in C++ immer mehr vereinfacht. Zeiger machen auf den Programmiereinsteiger anfangs einen etwas komplizierten Eindruck. Mit ein wenig Übung gewinnt man jedoch schnell den Überblick und ein Verständnis für die dahinterstehenden Konzepte. Die praktische Anwendung von Zeigern kann trotz detailliertem Verständnis der theoretischen Konzepte sehr fehleranfällig sein - einmal eine falsche Positionsnummer verwendet und man greift auf Speicher zu, der einem gar nicht gehört. Oder einmal ein delete vergessen und man gibt reservierten Speicher nicht ans Betriebssystem zurück.
Aufgrund der fehleranfälligen Arbeitsweise mit Zeigern wurden und werden laufend neue Werkzeuge in C++ erfunden, die das Arbeiten mit Zeigern wesentlich vereinfachen und somit zu einem robusteren Code beitragen sollen. In modernem C++-Code finden Sie daher kaum noch Zeiger. Diese verschwinden praktisch hinter Hilfsmitteln, die den Entwickler vor vielen Fehlern schützen, die er beim direkten Umgang mit Zeigern machen könnte. Das Problem ist leider, dass Sie für den Einsatz dieser Hilfsmittel sehr wohl verstehen müssen, was Zeiger eigentlich sind und wie Zeiger funktionieren. Obwohl also der direkte Einsatz von Zeigern immer mehr in den Hintergrund rückt, weil viele Hilfsmittel den Umgang mit Zeigern vereinfachen, ist dummerweise für den Einsatz dieser einfachen Hilfsmittel ein gutes Verständnis von Zeigern unerlässlich. So ist es zwar schön zu wissen, dass smart pointers existieren und die Zeigerproblematik vor dem Programmierer verbergen. Ohne ein detailliertes Verständnis von Zeigern werden Sie smart pointers aber nicht sinnvoll einsetzen können.
7.6 Aufgaben
Übung macht den Meister
Erstellen Sie eine C++-Anwendung, in der Sie dynamisch ein eindimensionales Array vom Typ
shorterstellen. Der Anwender Ihres Programms soll angeben können, aus wie vielen Elementen das Array bestehen soll. Legen Sie abwechselnd in alle Elemente des Arrays die Zahlen 0 und 1 hinein und geben Sie danach den Inhalt des Arrays auf den Bildschirm aus.